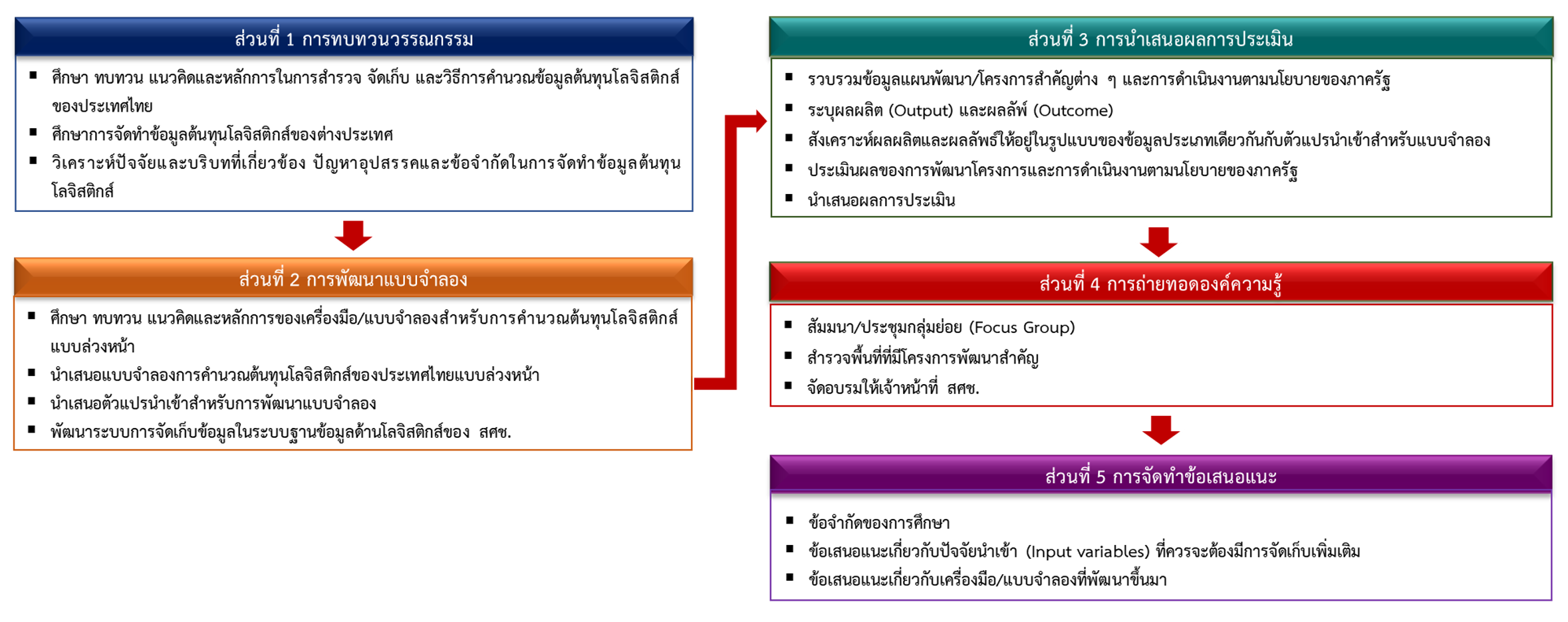
สำนักงานสภาพัฒนาการเศรษฐกิจและสังคมแห่งชาติ (สศช.) ร่วมกับหน่วยงานที่เกี่ยวข้องขับเคลื่อนการพัฒนาตามแผนยุทธศาสตร์การพัฒนาระบบโลจิสติกส์ของประเทศไทยมาอย่างต่อเนื่อง โดยมีตัวชี้วัด
ที่สำคัญ ได้แก่ สัดส่วนต้นทุนโลจิสติกส์ต่อผลิตภัณฑ์มวลรวมในประเทศ (GDP) ซึ่ง สศช. ได้จัดทำข้อมูลดังกล่าวมาตั้งแต่ปี 2547 โดยอาศัยข้อมูลทุติยภูมิจากตารางปัจจัยการผลิตและผลผลิตเป็นหลัก และต่อมาในปี พ.ศ. 2561 ได้มีการปรับปรุงนิยามและจัดเก็บข้อมูลเพิ่มเติมเพื่อให้การคำนวณมีความถูกต้องและสอดคล้องกับข้อเท็จจริงในปัจจุบัน รวมทั้งเป็นประโยชน์ให้หน่วยงานที่เกี่ยวข้องใช้เป็นเครื่องมือในการติดตามและประเมินผลการพัฒนาระบบโลจิสติกส์ในภาพรวมของประเทศ รวมทั้งเป็นข้อมูลประกอบการวางแผนและกำหนดยุทธศาสตร์การพัฒนาที่สามารถสนับสนุนการเพิ่มขีดความสามารถในการแข่งขันของประเทศ
แบบจำลองการคำนวณต้นทุนโลจิสติกส์ของประเทศไทย อ้างอิงวิธีการคำนวณต้นทุนโลจิสติกส์ของ Robert V. Delaney แห่งบริษัท Cass Information System ของสหรัฐอเมริกาเป็นหลัก อย่างไรก็ตาม
ยังมีข้อจำกัดบางประการ เนื่องจากข้อมูลบางส่วนมีองค์ประกอบของตัวแปรที่ยังไม่มีระบบการจัดเก็บชัดเจนขาดการสำรวจและรวบรวมข้อมูลในระดับประเทศ และการจัดเก็บข้อมูลในหลายกิจกรรมทำได้ยากในทางปฏิบัติ ทำให้ต้องอาศัยวิธีการประมาณค่าตัวแปรมาประยุกต์ใช้ตามมาตรฐานวิธีการทางสถิติและวิธีการคิดของต่างประเทศ นอกจากนี้ การประมาณการสัดส่วนต้นทุนโลจิสติกส์ต่อ GDP ของประเทศไทยในปัจจุบันเป็นการประมาณการ โดยใช้ข้อมูลนำเข้า (Input data) จากข้อมูลทุติยภูมิ จากหน่วยงานที่เกี่ยวข้องที่มีการจัดทำข้อมูลเป็นประจำทุกปี ทั้งจากการติดต่อประสานโดยตรงกับหน่วยงานนั้น ๆ หรือจากรายงานประจำปีที่มีการเผยแพร่และมีระยะเวลาในการรอข้อมูลนำเข้า จึงทำให้ข้อมูลสัดส่วนต้นทุนโลจิสติกส์ต่อ GDP เป็นตัวชี้วัดตาม (Lagging indicator)
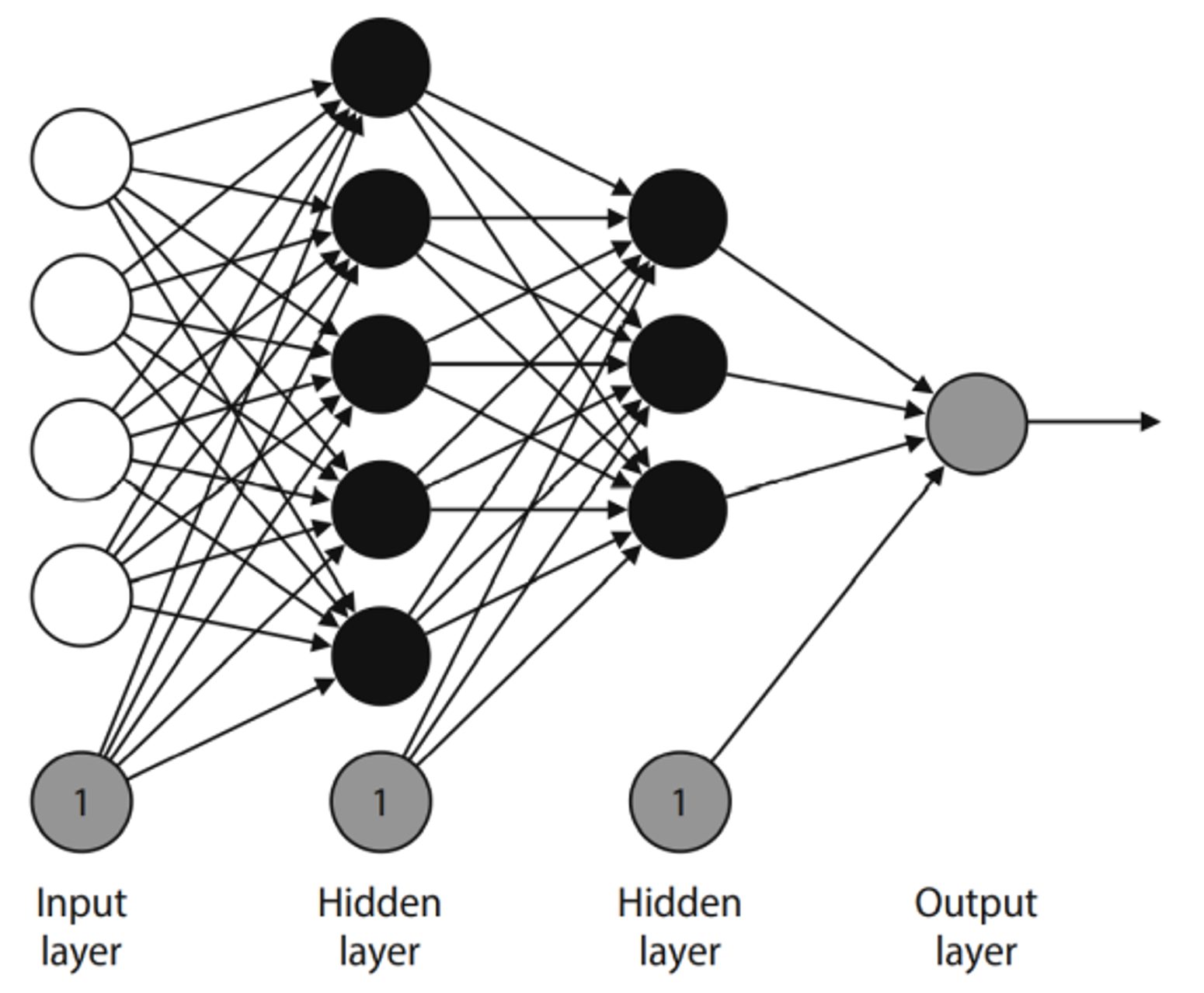
ดังนั้น สศช. ในฐานะหน่วยงานรับผิดชอบหลักในการจัดทำข้อมูลต้นทุนโลจิสติกส์ต่อผลิตภัณฑ์มวลรวมในประเทศ (GDP) จึงมีความจำเป็นต้องดำเนินการจ้างที่ปรึกษาเพื่อเป็นค่าใช้จ่ายในการพัฒนาแบบจำลองการคำนวณต้นทุนโลจิสติกส์ของประเทศไทยแบบล่วงหน้า (Predictive Model) เพื่อศึกษา สำรวจ และพัฒนาแบบจำลองการคำนวณต้นทุนโลจิสติกส์ที่สามารถประมาณการข้อมูลที่มีความเป็นปัจจุบันและสามารถประมาณการข้อมูลล่วงหน้า (Leading indicator) สำหรับใช้เป็นเครื่องมือในการวิเคราะห์และประเมินผลแผนงานโครงการและมาตรการที่เกี่ยวข้องกับการพัฒนาระบบโลจิสติกส์ รวมทั้งใช้เป็นข้อมูลประกอบการตัดสินใจวางแผน กำหนดนโยบาย และขับเคลื่อนการพัฒนาระบบโลจิสติกส์ประเทศให้มีประสิทธิภาพ